
基本概念
1 | //默认容量 16 |
- 加载因子0.75的意思是这个表超过75%容量的时候,就会扩容。0.75是一个经过大量实验测算得出的比较好的值,不要问为什么不是0.6或者0.8什么的……
- HashMap的底层jdk1.8后是“数组+链表+红黑树”,之前是“数组+链表。说白了就是默认长度为16的数组,每个元素存储的是一个链表或者是红黑树的头结点。
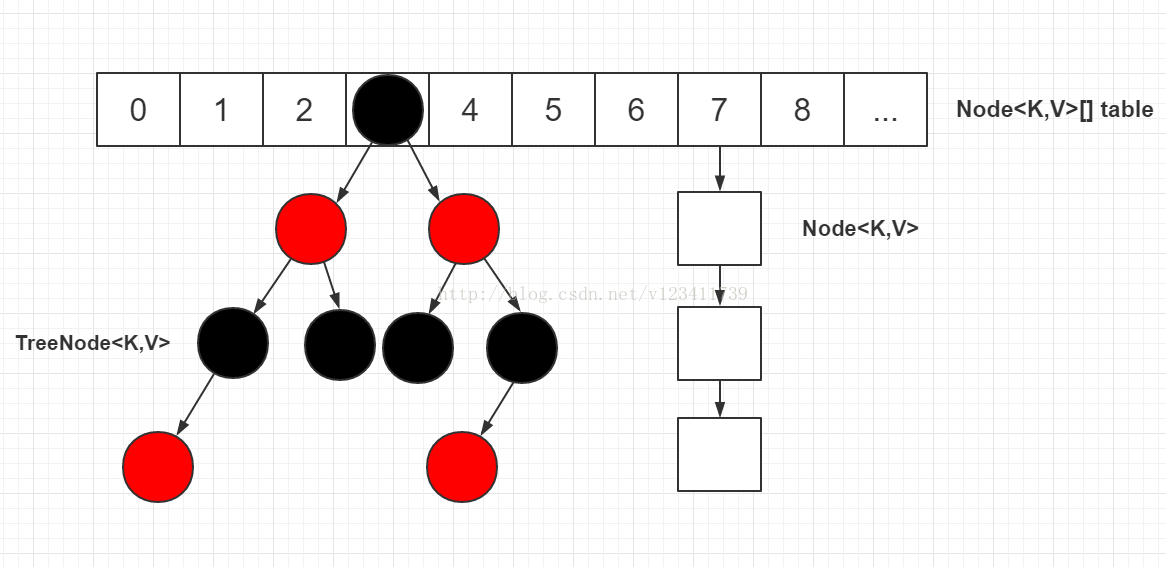
- 哈希碰撞指的是key不同,但是计算的hash值相同或者在数组中的索引值相同了。HashMap来解决这个问题就是用了链表。当碰撞很多时,HashMap就退化成了一个链表,查询时间0(n)。在jdk1.8开始呢增加了红黑树(查询时间O(logn))这种数据结构,在碰撞结点较少时,就采用链表,当碰撞结点较多时,就转为红黑树。
- HashMap是线程不安全的。HashTable是线程安全的,因为添加了synchronized关键字来确保线程同步。
源码分析
- 构造方法
1 | public HashMap(int initialCapacity, float loadFactor) { |
hash值的计算
1
2
3
4
5
6
7
8
9//计算hash值:将hashCode与hashCode的高16位异或运算
//为什么要用高16位来运行,其实也是为了减少哈希碰撞
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//计算在数组中的索引
(n - 1) & hashput操作
1 | public V put(K key, V value) { |
- get
1 | final Node<K,V> getNode(int hash, Object key) { |
- 扩容
1 | final Node<K,V>[] resize() { |
那么我们肯定想知道HashMap是什么时候扩容的?
1 | 1.数组空的时候后会扩容 |
那么为什么要扩容?
1 | 1. HashMap中元素个数实在太多了,已经很频繁的发生hash冲突, |
补充ConcurrentHashMap
jdk1.8之后,ConcurrentHashMap的底层也是数组+链表+红黑树。我们知道HashMap是线程不安全的,而HashTable只是简单的在方法上加锁实现线程安全,效率低下,所以在线程安全的环境下我们通常会使用ConcurrentHashMap。这里我们主要想看下为什么ConcurrentHashMap是线程安全的。
- 先看下初始化数组的操作
1 | CAS是乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时, |
1 | private final Node<K,V>[] initTable() { |
- 计算hash值
1 | static final int spread(int h) { |
- put操作
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
1 | put操作如何保证线程安全的呢? |
- 移除
1 | public V remove(Object key) { |
5.get方法
1 | public V get(Object key) { |
1 | get操作保证线程间的可见性即可 |
- 扩容
1 | final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { |
1 | 1. 扩容时假如有个线程在get操作,而且操作的下标一样呢? |

